这篇只是作为学习笔记之用,记录复习中的一些知识,算法设计也均是伪代码表示,如果你想要找代码实现就不必看这些内容了,不过如果想要简单回顾一下相关知识还是可以浏览一下的。如果时间不仓促每个算法实现一下还是挺好的,不过这都是考试结束之后的事情了~
图的分类
图分为有向图和无向图,两种都可以表示为G={V,E},分别是顶点和边,有向无向均是针对边来说的。
下面的lgE=lgV是同一个数量级的这个在最小生成树算法的算法复杂度分析中比较重要,所以这里罗列出来。
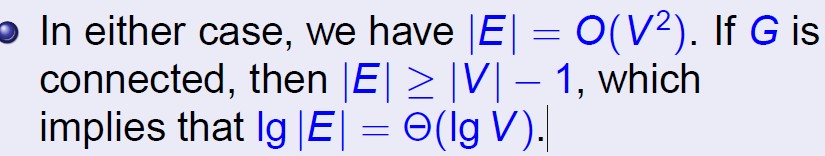
图的两种表示方法
图的表示方法有两种,邻接链表和邻接矩阵:
邻接链表有一个握手定理,就是遍历邻接表中所有点的邻接点,在无向图中需要2E次,有向图中需要E次。这里在图的算法分析中还是比较重要的。如下:

留下两个思考题:
针对邻接矩阵表示的图和邻接链表表示的图G,进行反转的时间复杂度分别是多少呢?
针对邻接矩阵,直接进行0转1,1转0即可,时间复杂度矩阵的大小;
但是邻接链表?我自己的思路是重新构造一个邻接链表,新的链表顶点,针对顶点1,把它加入到其后邻接点的作为顶点,依次类推,这个时间复杂度为E;
针对邻接矩阵表示的图和邻接链表表示的图G,将图中路径为长度为2的点进行连接这种图的变换的时间复杂度分别是多少呢?
针对邻接矩阵,同样比较简单,直接将矩阵平方即可,时间复杂度为矩阵乘法的时间复杂度;
邻接链表也只是我个人理解的一个思路:重新构造一个邻接链表,第一个遍历链表后面元素的链表...有点绕,但是就是顶点的邻接顶点作为顶点的邻接顶点,但是要有去重的工作,没有去重则为2E;以上仅是我个人理解,有什么不对可以反馈。
广度优先搜索
图的搜索算法都是根据标记颜色来进行的,接下来的深度优先搜索也是有颜色的标记。
伪代码:
BFS(G,s) for each vertex u in V[G]-s color[u]=white father[u]=NIL depth[u]=MAX color[s]=gray depth[s]=0 father[s]=NIL Q=NULL ENQUEUE(Q,s) while(Q!=NULL) u=DEQUEUE(Q) for each v in Adj[u] if color[v]=white color[v]=gray depth[v]=depth[u]+1 father[v]=u ENQEUE(Q,v) color[u]=black
时间复杂度分析

广度优先树
广度优先搜索形成一个树的结构,其定义如下由上面形成的father结构形式

可以递归的输出广度优先树的到达开始节点的路径,这个路径也是最短路径。
BFS思考题:

思路一:一个点BFS找到一个最远的点,然后从这个最远的点开始BFS,到达的最远的一个点的距离及为直径
思路二:根据根节点分为左子树和右子树,然后左子树的高度+1+右子树的高度为直径?
深度优先搜索
深度优先搜索有一个时间戳的标识
深度优先搜索一般截图图的连通问题~!
伪代码:
DFS(G) for each u in V[G] color[u]=white father[u]=NIL time=0 for each u in V[G] if color[u]=white DFS-VISIT(u)DFS-VISIT(u) color[u]=gray d[u]=time=time+1 for each v in Adj[u] if color[v]=white father[v]=u DFS-VISIT(v) color[u]=black f[u]=time=time+1
时间复杂度:

DFS的两个性质:
时间包含,子节点和完全包含是充要条件
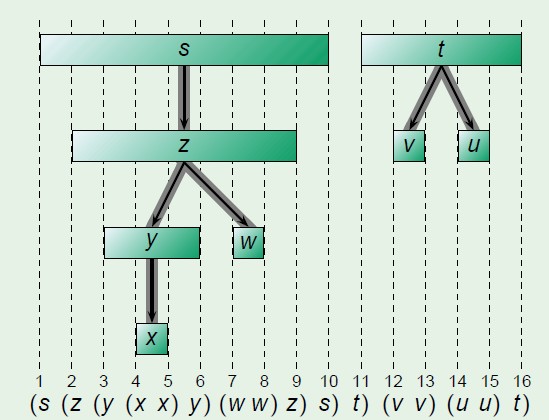
白色路径定理,后面的证明会用到

DFS中碰到的四种边的分类以及识别算法:
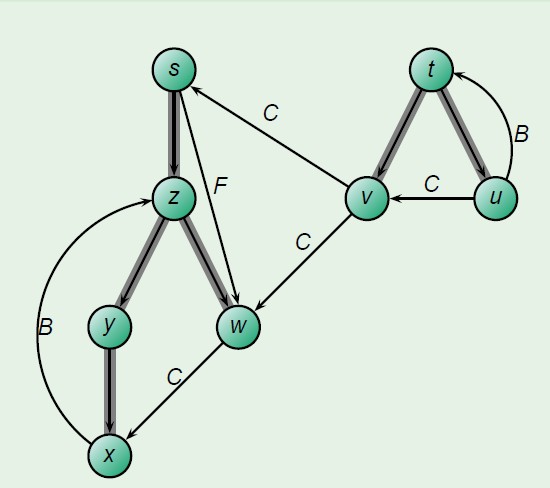
算法思想描述:可以对算法DFS做一些修改,使之遇到图中的边时,对其进行分类,算法核心思想在对于每条边u,v,当该边被第一次寻到时,根据所到达顶点的颜色,对其分类。
1、白色的表明是树边2、灰色的表明是回边3、黑色的表明是正向边或者交叉边如果du<dv正向边,du>dv交叉边拓扑排序:
伪代码:

强连通分量识别:
伪代码:

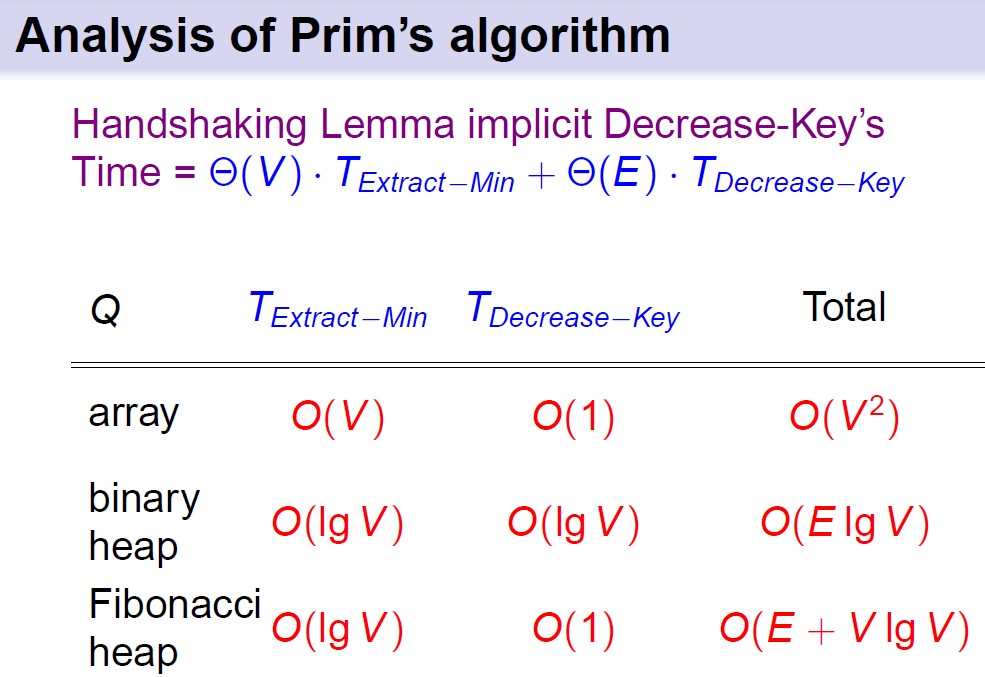
最小生成树


算法时间复杂度分析:



算法时间复杂度分析:

最后太仓促了,本来写好了,电脑又蓝屏了,导致就草草的收尾了,真是可惜哪些写过的,要考试了还是花时间多复习一下。